Have you ever considered the why people who speak with a foreign accent are sometimes quite difficult to understand? Or why one might mistake a young child’s whining for a cat’s meow? Maybe you have been surprised to realize that the lyrics to one of your favorite songs were not at all what you thought you had been hearing for years?
The process of recognizing speech is fascinating, incorporating and manipulating elements of physical, visual, audio, and semantic information. And this generally occurs unconsciously and over a matter of milliseconds.
In this tutorial, we will look at several theories and models, each accounting for various aspects of speech perception by addressing questions such as:
-how syllables and words are segmented
-how we use integrate audio and visual information
-how we perceive categories of sounds based on features
-how the rate of speech affects perception
-how interfering noise affects perception
At this point, take a moment to read our brief tutorial on Lexical Retrieval and the Architectures of Speech Processing Models
The perception and recognition of speech sounds is the very first stage of language processing. As soon as sound waves reach your hearing apparatus, neurons begin making connections between the perceived sound and a plausible match that you have stored in your lexicon (mental dictionary). Several theories have been proposed as to how and what a listener actually identifies in a speech sound. The Motor Theory (Liberman), the Auditory Theory, and the Direct Realist Theory (Fowler, 1986) are the three most prominent systems.
The Motor Theory (MT) claims that listeners identify sounds by linking acoustic patterns with articulatory gestures. In other words, physical acoustic signals, such as sound waves and formant frequencies, are interpreted based on which articulators are used to control the airflow through the vocal tract. So your brain actually registers, voiceless glottal fricative, front lax vowel, lateral liquid, etc. when someone simply says, ‘hello’. Quite complex! Since human speech is species specific, (humans alone produce speech sounds) and since this is an innate ability, those who subscribe to the MT claim that the brain uses separate components to process speech as opposed to other sounds, i.e., barking dogs, slamming doors, sirens, etc. This is considered a passive process since decoding acoustic signals occurs naturally in humans and is localized to a specific ‘speech’ element in the brain. Categorical Perception and the McGurk Effect both support the MT.
The Auditory Theory (AT) posits that speech perception occurs as part of a general auditory system that is not species-specific. Thus we match incoming speech signal patterns with representations of sounds that we have already heard and have stored as templates. So instead of linking acoustic signals to articulatory gestures, we link them to acoustic representations.
This is considered an active process since the brain must make connections between articulatory gestures and perceived units of speech and distinguish them from other non-speech sounds.
The Direct Realist Theory (DRT) postulates we perceive the properties of a speech signal directly as sounds are articulated. So instead of hearing sounds as specific and intentional articulatory gestures, we perceive them as movements of the lips, tongue, teeth, etc. directly. Thus perception involves a direct link to the source of the sound, not the articulators that are used in producing the sound. Thus no knowledge of the articulatory or phonological systems is necessary in perceiving speech.
A Theory or Two
In linguistics, categorical perception (Liberman et al., 1957) is the term used to explain the fact that humans categorize speech sounds according to distinctive features. Tests are set up as a continuum of sounds along a spectrum in which the increments of change are not perceptible. However, listeners will distinguish when category boundaries have been crossed. For example, voice onset time (VOT) is the distinguishing feature between /t/ and /d/. As long as the sounds remained within the boundaries of /t/, no variations of VOT were detected. However, listeners recognized when /t/ transitioned to /d/ (the VOT is altered from 0 for /t/ to negative for /d/. In other words, perception is not gradual, but discrete. This theory supports the fact that articulatory gestures are a significant factor in the perception of speech sounds.
Fuzzy Logical Model of Perception (Massaro, 1989) posits that perception is not always based on binary features, (e.g., zero vs. negative VOT) but on larger units as prototypes. In other words, there is a fuzzy, or unclear value (again, not binary) given to as sound as to how likely it belongs to any given category. Perception is, again, based on articulatory features, however, several of these, or of other sources (see McGurk Effect) can combine to create larger ‘categories’. Thus, during the perception process, information from more than one source is accessed until there is a reasonable match between the stimulus and the all the information the listener has about a specific prototype.
McGurk Effect
McGurk and MacDonald (1976) recorded a video showing someone producing the syllable /ga/, but they superimposed the sound /ba/, resulting in listeners hearing /da/. The incongruence between what was seen and heard with what was perceived demonstrated that the brain merges auditory and visual information into a single unit of perception.
The Ganong Effect (Ganong, 1980) proposed that the process of speech perception leans heavily on the lexicon. In phonemic restoration tasks in which two words were presented, one real, one nonce, and in which the initial phonemes were distinguished by only one feature, listeners always perceived the real word (task was selected over dask, kiss was selected over giss). Thus he showed that phoneme identification includes information at the lexical level.
The Logogen Model (Morton, 1969) states that each lexical entry contains a recognition unit called a ‘logogen’ that specifies a word’s orthographic, phonological, and semantic properties. Logogens are activated by phonetic and semantic input, which is entered into the logogen system. Recognition occurs when the threshold for the output word is reached and is affected by frequency. In other words, high frequency words require less incoming information to reach their threshold since they are recognized more quickly than low frequency words.
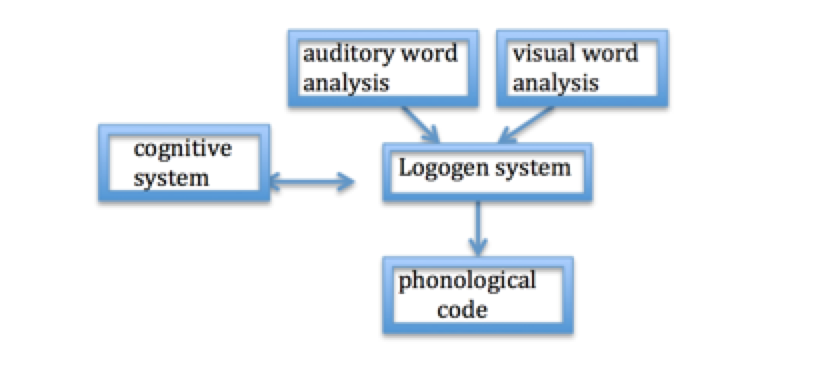
Figure 1 The Logogen Model
The Cohort Model was Marslen-Wilson (1989) developed in response to questions surrounding Morton’s Logogen model and Forster’s Search model. The Cohort Model is an autonomous, distributed and non-localist architecture composed of 3 stages, access, selection (pre-lexical), and integration (post-lexical), and focuses on the sensory or gestural information as the essential component of the access and selection processes.
Access to potential candidates of cohorts is based uniquely on the speech signal (autonomous) that will activate all lexical items (words) that begin with the same initial sounds. This is the most intense stage of perception.
During the selection stage, one ‘cohort’ of words becomes activated. Continuing incoming acoustic information will cause mismatches between all the words in the cohort. Mismatches are eliminated sequentially until only the target word remains. This is referred to as the uniqueness point.
During these initial two stages, there are strict constraints on the affects of context thus prohibiting any top-down interference. Only sensory input is used in selecting one candidate from the generated cohort.
It is not until the integration stage that context is accessed. At this point in perception, semantic and syntactic properties are used to integrate the selected word into the context of the phrase in which it is being used.
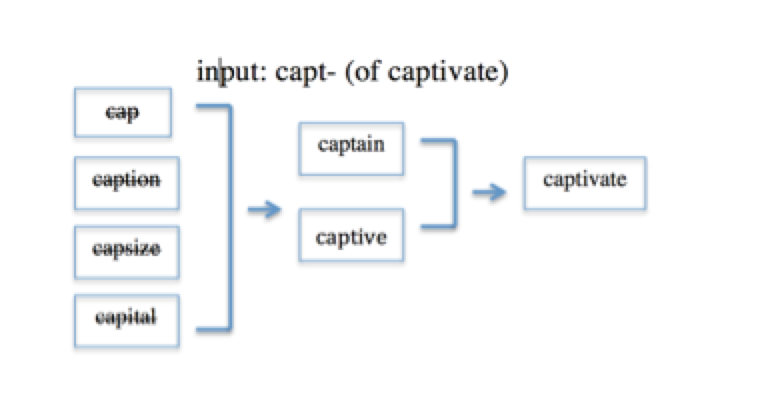
Figure 2 The Cohort Model
The Neighborhood Activation Model (NAM) (Luce, 1986; Luce & Pisoni, 1998) accounts for spoken word recognition along the lines of the Cohort Model. According to this model, all phonologically similar words are stored in neighborhoods. The more words stored, the denser the neighborhood.
Recognition of a word is based probability factors between the stimulus and all the other words in the neighborhood, such as frequency of usage of the target words as well as the size of its neighborhood. For instance, if the stimulus word activates a large number of words that are phonetically similar, recognition will be slower than if the neighborhood activated is smaller. Recognition will also be slower if the stimulus activates other high frequency neighbors.
TRACE (McClelland and Elman, 1986) is an interactive network model of speech perception based on the notion that perception occurs through a network of neurons in which different levels of speech units (e.g., features, phonemes, words) are represented on different levels. At the input level, where features and phonemes are accessed, the system is bi-directional; i.e., activation can move between layers.
As input is received, phonemic features are activated, phonemes are recognized, and an excited phoneme will then excite the word units to which it is connected. This is excitatory activation across levels. However, there is also an inhibitory effect within each level. For example, at the phoneme level, the activation of one phoneme inhibits the activation of other competing phonemes.
Unlike other models, TRACE can ‘recover’ if elements of the speech signal are missed. There are two different ways recovery can happen. First, TRACE does not rely on the initial sounds of the input the way the Cohort Model and NAM do, therefore, if the initial sounds are missed, recovery is still possible for TRACE. TRACE’s bidirectional connections permit the use of top-down processing, which integrates context to facilitate speech perception.
Throughout the retrieval process, ‘traces’ of inhibited units from a previous level are left activated for a certain amount of time. This permits the speaker to return to the point where an error is perceived, without needing to begin the process at the initial level. The advantage to these traces is that processing does not have to start from the beginning, but can pick up at the most recent point.
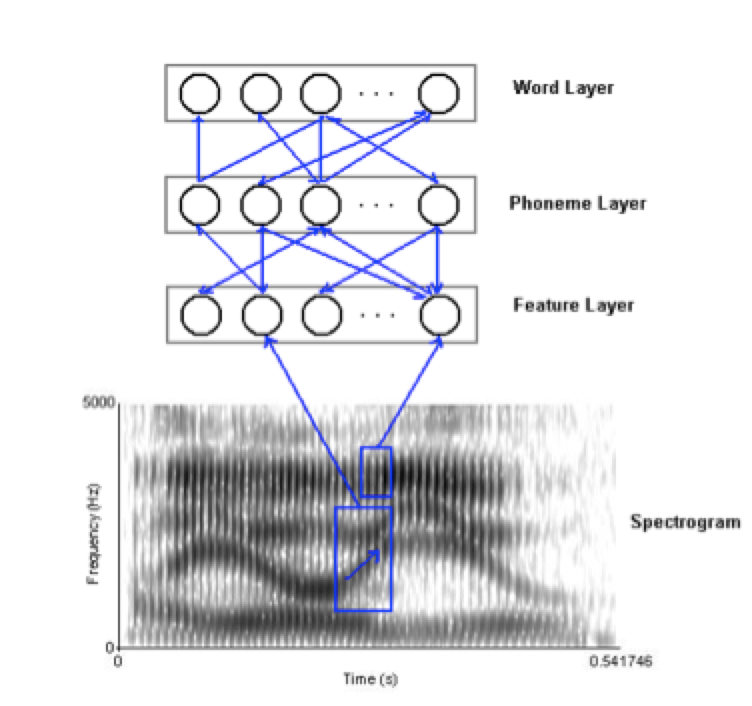
Figure 3 The TRACE Model showing activation moving from the feature to the word level.

Figure 4 The TRACE Model showing full cascading and top-down processing.
This is a large amount of information that is not necessarily intuitive for most students. Remember that this is an introduction to the more prominent models. For more in-depth information, go to our Psycholinguistics Scholarly Articles or click on the links provided in this tutorial.